 Actively Managed Equity
Actively Managed Equity Overview: All Strategies
Overview: All Strategies Investor Resources
Investor Resources Indexed Equity
Indexed Equity Private Equity
Private Equity Digital Assets
Digital Assets Invest In The Future Today
Invest In The Future Today
 Take Advantage Of Market Inefficiencies
Take Advantage Of Market Inefficiencies
 Make The World A Better Place
Make The World A Better Place
 Articles
Articles Podcasts
Podcasts White Papers
White Papers Newsletters
Newsletters Videos
Videos Big Ideas 2024
Big Ideas 2024


Increasingly, data centers require tailored hardware to meet the performance needs of artificial intelligence (AI) applications. Historically dependent on central processing units (CPUs), the traditional data center now relies on AI accelerators.[1] Accelerator designs are optimized for specific use cases, in this case neural network training and inference. ARK believes the demand for hardware to power AI use cases will reach $1.7 trillion in revenue by 2030, largely driven by the massive productivity gains associated with AI-enabled software.
Thanks primarily to Nvidia, the performance of AI training accelerators has been advancing at an astounding rate. Compared to the K80 chip that Nvidia released in 2014, the latest accelerator delivers 195x the performance on a total cost of ownership (TCO) adjusted basis, as shown below. TCO measures an AI training system’s unit price and operating costs.
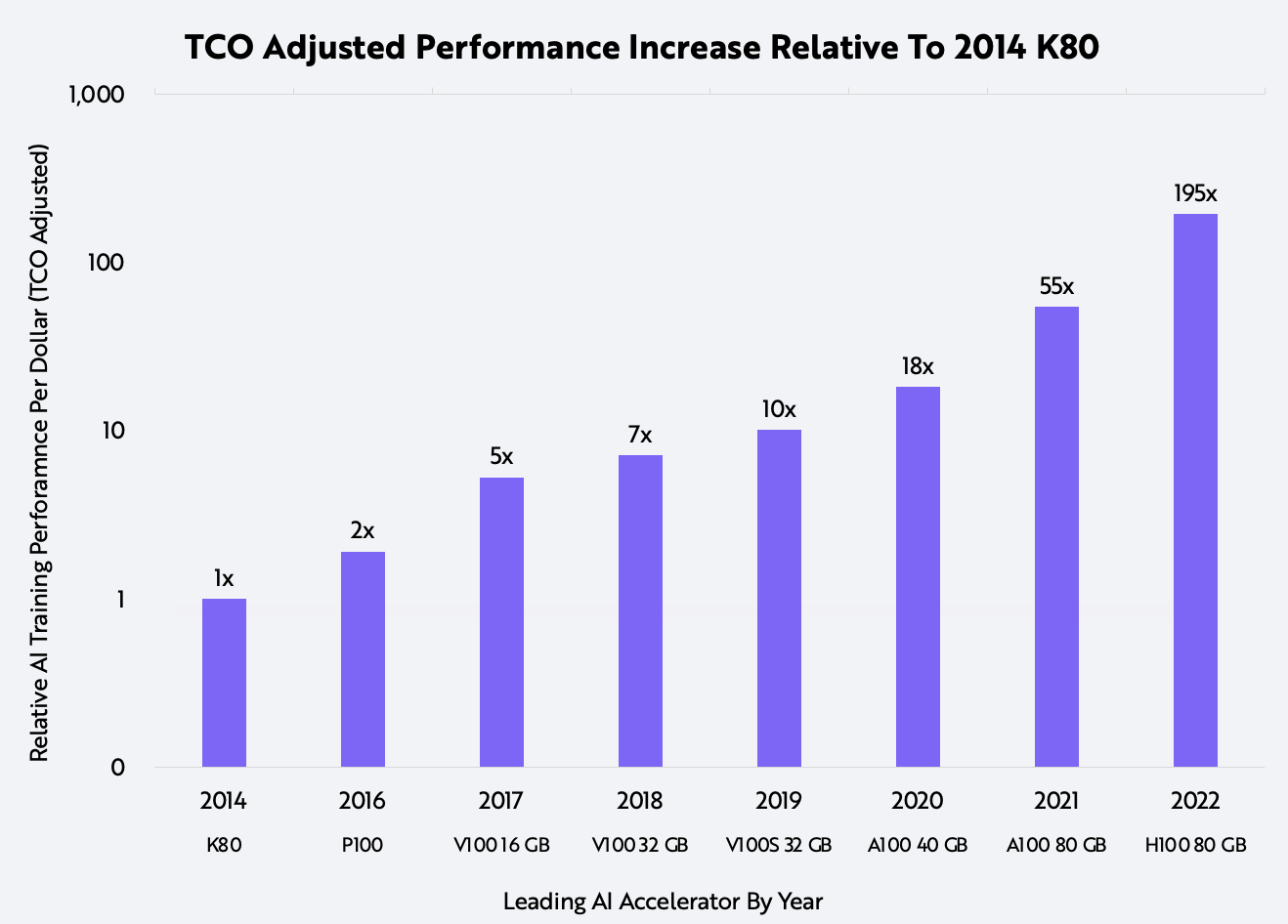
Source: ARK Investment Management LLC, 2022, based on data from Nvidia and the TechPowerUp GPU Database.
Forecasts are inherently limited and cannot be relied upon. For informational purposes only and should not be considered investment advice or a recommendation to buy, sell, or hold any particular security.
What explains such rapid performance improvements? As a baseline, Moore’s Law predicts that the number of transistors on a chip doubles every 18 months to two years. Although the accuracy of Moore’s Law’s prediction has diminished in recent years, historically it has translated into a ~30% annualized decline in costs, which is much slower than AI-specific hardware’s cost decline. According to our estimates, AI chip performance has improved at a 93% rate per year since 2014, translating into a cost decline of 48% per year, as illustrated in the table below. Measuring the time to train large AI models instead of Moore’s Law, we believe transistor count will become more important as AI hardware chip designs increase in complexity.
| K80 | P100 | V100 32 GB | A100 40 GB | H100 | CAGR | |
|---|---|---|---|---|---|---|
| Architecture | Keplar | Pascal | Volta | Amphere | Hopper | |
| Release Date | 2014 | 2016 | 2018 | 2020 | 2022 | |
| Relative Compute Units (RCUs) | 1 | 3 | 12 | 38 | 587 | |
| Estimated Unit Cost* | $5,000 | $10,500 | $12,000 | $15,000 | $19,500 | |
| Estimated TCO** | $11,408 | $15,840 | $18,408 | $23,544 | $34,452 | |
| TCO $ / RCU | $11,408 | $5,280 | $1,601 | $620 | $59 | -48% |
*Nvidia’s official pricing is not public and varies by customer. Estimates derived from industry researchers. **A total cost of ownership estimate inclusive of power, cooling, and other operating overhead over 3-year useful life is applied.
Source: ARK Investment Management LLC, 2022, based on data from Nvidia and the TechPowerUp GPU Database. For informational purposes only and should not be considered investment advice or a recommendation to buy, sell, or hold any particular security.
Shrinking the process size from 28 nanometers to 4 nanometers and increasing the transistor count tells only part of the story, as shown below.
| K80 | P100 | V100 32 GB | A100 40 GB | H100 | CAGR | |
|---|---|---|---|---|---|---|
| Process Size (nm) | 28 | 16 | 12 | 7 | 4 | |
| Transistors (mm) | 14,200 | 15,300 | 21,000 | 54,200 | 80,000 | 24% |
Source: ARK Investment Management LLC, 2022, based on data from Nvidia and the TechPowerUp GPU Database.
For informational purposes only and should not be considered investment advice or a recommendation to buy, sell, or hold any particular security.
In addition to transistor count, advances in core architecture, high speed memory capacity, and interconnect bandwidth are combining to deliver exponential performance gains well beyond that associated with Moore’s Law.
Training neural networks requires many compute-intensive matrix multiplications. To accelerate them, Nvidia has been leveraging tensor cores designed specifically for matrix multiplications since their debut on the Volta architecture in 2018. The H100 now delivers up to 2 petaflops of tensor performance, a 16x increase over the 125 teraflops on the V100 launched in 2018, as shown below.
| K80 | P100 | V100 32 GB | A100 40 GB | H100 | CAGR | |
|---|---|---|---|---|---|---|
| Minimum Precision | FP32 | FP16 | FP16 | FP16 | FP8 | |
| Max Teraflops | 8.7 | 18.7 | 125 | 312 | 2000 | 97% |
Source: ARK Investment Management LLC, 2022, based on data from Nvidia and the TechPowerUp GPU Database.
For informational purposes only and should not be considered investment advice or a recommendation to buy, sell, or hold any particular security.
Tensor cores also have evolved. Over time, researchers have learned that neural networks can be trained effectively using a mix of lower precision floating point operations, without losing accuracy. Low precision floating point operations (FP16 and FP8) are faster than high precision operations (FP32 and FP64). Leveraging FP8 precision, for example, Nvidia’s latest generation tensor core on the H100 accelerator delivers up to 9x more performance speed than the prior generation.
As the number of modeled parameters and pools of training data has scaled, Nvidia has added more memory to its chips, enabling larger batch sizes when training. The latest generation of ultra-high bandwidth memory technology, HBM2e, is much faster than the GDDR5 memory found in Nvidia’s 2014 K80. With 80 gigabytes of HBM2e memory, Nvidia’s H100 can deliver 6.25x the memory bandwidth of the K80, as shown below.
| K80 | P100 | V100 32 GB | A100 40 GB | H100 | CAGR | |
|---|---|---|---|---|---|---|
| Memory (gb) | 24 | 16 | 32 | 40 | 80 | 16% |
| Memory Bandwidth (tb/s) | 0.48 | 0.732 | 0.9 | 1.55 | 3 | 26% |
Source: ARK Investment Management LLC, 2022, based on data from Nvidia and the TechPowerUp GPU Database.
Forecasts are inherently limited and cannot be relied upon. For informational purposes only and should not be considered investment advice or a recommendation to buy, sell, or hold any particular security.
Lastly, as large models have scaled beyond the level a single chip can train, and because matrix multiplications are parallelizable, chip-to-chip communication and node-to-node bandwidth sharing are accelerating the move to distributed computation. Nvidia’s latest generation interconnect systems––NVLink for chip-to-chip communication and NVSwitch for node-to-node communication––allow many servers, each composed of many accelerators, to function as unified computational power, as shown below.
| K80 | P100 | V100 32 GB | A100 40 GB | H100 | CAGR | |
|---|---|---|---|---|---|---|
| Interconnect | PCIE 3.0 | NVLink v1 | NVLink v2 | NVLink v3 | NVLink v4 | |
| Max Bandwidth (GB/s) | 32 | 160 | 300 | 600 | 900 | 52% |
Source: ARK Investment Management LLC, 2022, based on data from Nvidia and the TechPowerUp GPU Database.
Forecasts are inherently limited and cannot be relied upon. For informational purposes only and should not be considered investment advice or a recommendation to buy, sell, or hold any particular security.
To understand the combined impact of these advancements, we assessed the annual performance improvement with a relative unit of compute (RCU) benchmarked to Nvidia’s 2014 K80 accelerator. With this benchmark, we modeled the cost declines of AI hardware using Wright’s Law.
While studying production costs during the early days of airplane manufacturing in the 1920s, civil aeronautics engineer Theodore Wright determined that for every cumulative doubling in the number of airplanes produced (1 to 2, 2 to 4, 4 to 8, etc.), costs declined 15%. ARK has applied Wright’s Law to various technologies including industrial robots, lithium-ion batteries, and electric vehicles.
Based on a combination of industry estimates, product documentation, and data from Nvidia’s public financial statements, we were able not only to approximate the production volume and unit cost decline of RCUs over time but also the total cost of ownership per RCU, as shown below. The results corroborated Wright’s Law, specifically a 37.5% decline in cost for every cumulative doubling in the number of RCUs produced, which is equivalent to a 48% compound annual rate of decline in costs since 2014.
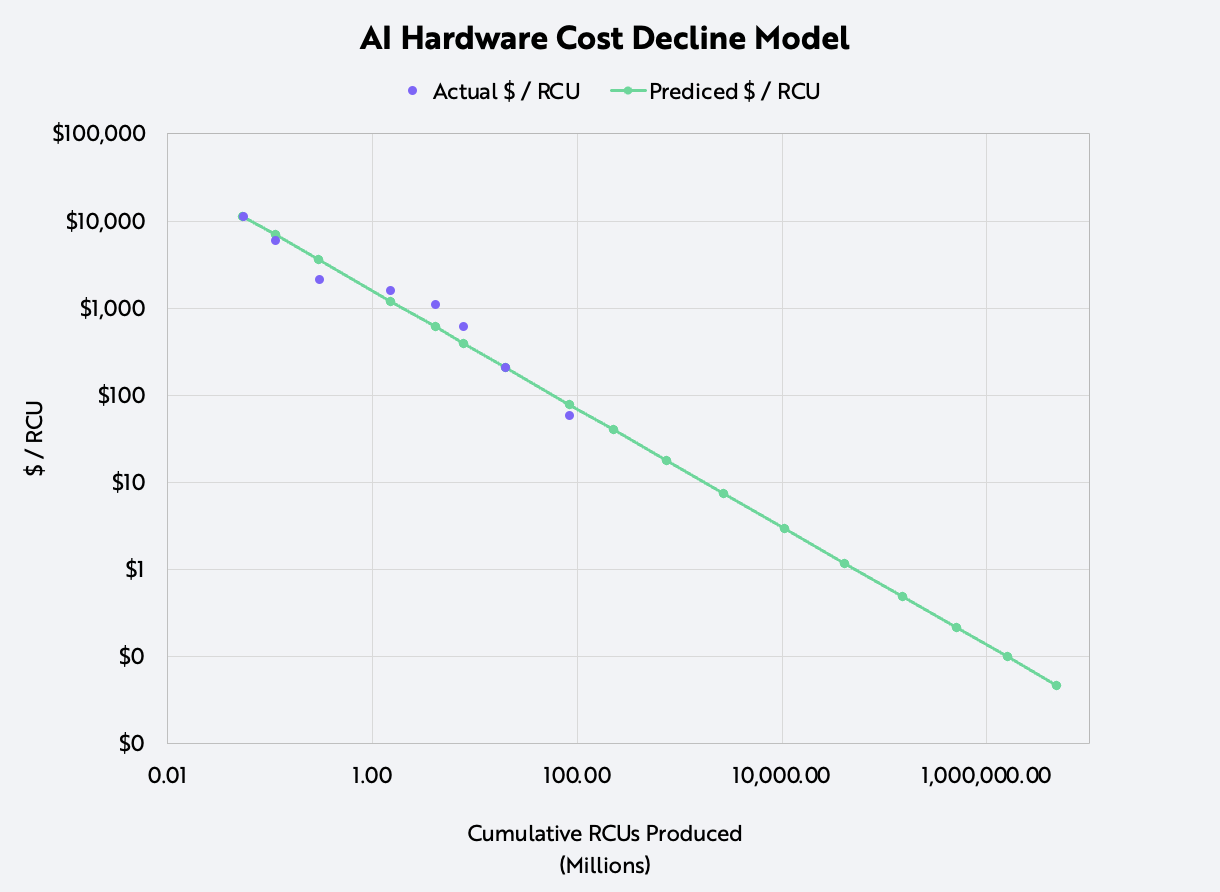
Source: ARK Investment Management LLC, 2022, based on data from Nvidia, the TechPowerUp GPU Database, and The Next Platform.
Forecasts are inherently limited and cannot be relied upon. For informational purposes only and should not be considered investment advice or a recommendation to buy, sell, or hold any particular security.
Extending this model, we estimate that the cost for performance equivalent to an Nvidia K80 chip will have dropped astonishingly from $11,000 in 2014 to 5 cents in 2030.
Although Nvidia created and leads the market for AI accelerators, many challengers are likely to enter the market during the next eight years. Venture funding for chip startups has doubled in the last five years, and Tesla’s Dojo supercomputer is a contender that is vertically integrating into the AI hardware layer to train its neural nets and maximize performance.
Related Research


