Actively Managed Equity
Actively Managed Equity Overview: All Strategies
Overview: All Strategies Investor Resources
Investor Resources Indexed Equity
Indexed Equity Private Equity
Private Equity Digital Assets
Digital Assets Invest In The Future Today
Invest In The Future Today
 Take Advantage Of Market Inefficiencies
Take Advantage Of Market Inefficiencies
 Make The World A Better Place
Make The World A Better Place
 Articles
Articles Podcasts
Podcasts White Papers
White Papers Newsletters
Newsletters Videos
Videos Big Ideas 2024
Big Ideas 2024

According to IDC, the quantity of data created, replicated, and consumed is doubling every two years. It is no wonder that in 2012 only two percent of worthwhile data was analyzed. During the next two days, the quantity of information produced globally will equal the total produced in the history of all time through 2003. Technology has been struggling to keep up with this demand.
While the quantity of data is rising exponentially, the quality is changing rapidly as well. The shift from clear-cut structured data to amorphous unstructured data is complicating everything from computing power to storage and analytics. Structured data typically exists in frameworks with well-defined variables and values, while unstructured data lacks pre-defined organization and can be anything from the content of a tweet to images or audio.
Structured data played an integral role in the 1990s when Oracle [ORCL], IBM [IBM], Microsoft [MSFT] and SAP [SAP] lead the evolution of relational database management systems (RDBMS). Such companies provided the software and often the hardware, both of which had to be bought at a premium, to crunch through large databases of structured information. While RDBMS still play a large role in enterprise data analysis, 80% of new data growth is unstructured, and therefore largely inaccessible to these databases. Furthermore, the proprietary machines associated with RDBMS are struggling to scale fast enough to provide adequate storage and computing power for increasingly large datasets.[1]
The problems facing the data industry will not be solved by incremental improvements and adjustments. They demand an entirely new approach.
Fortunately, Apache Hadoop, a popular open source software project curated by the respected Apache Software Foundation and proliferated by various commercial distributors, provides such an approach. Its muddled beginnings date back to 2002, but it has evolved at an astonishing rate. Transparency Market Research estimates that the Hadoop market will grow from $1.5B in 2012 to $20.9B in 2018, compounding at an annual growth rate of 55%. Notably, Hadoop works with both structured and unstructured data, enabled by massive parallel processing (MPP). Not reliant on expensive proprietary hardware, it leverages off of cheap clustered commodity servers and is comprised of three primary elements: Hadoop Distributed File System (HDFS), MapReduce, and YARN.
HDFS is the core information reservoir for Hadoop. As a file system instead of a database, HDFS is flexible and can incorporate both structured and unstructured data. Data are broken into blocks and distributed across a number of servers, sometimes thousands housing hundreds of petabytes of information. HDFS also replicates redundant data blocks on multiple servers, providing reliability and backup in the case of server failure.
MapReduce is Hadoop’s classical compute engine for “mapping” and “reducing,” which processes huge amounts of data via divide and conquer. In order to minimize the movement of huge datasets, processing software moves to the data instead of data moving to the processor. In the mapping stage, each server is assigned data blocks from HDFS to create lists of occurrences, or key-value pairs. In the reduce stage, all of the lists are compiled to ascertain the aggregate values per key.Massive parallel processing allows all servers to work simultaneously on this process.
YARN, or Yet-Another-Resource-Negotiator, is a recent integral addition to Hadoop, added for general availability in October 2013’s Hadoop 2 release. While it is referred to as MapReduce 2 by the Apache Software Foundation, YARN has not made the original MapReduce irrelevant, but instead downgraded it to one way of many to mine data within Hadoop.
The best way to think of YARN is as Hadoop’s operating system, as it schedules interactions among diverse data storage, mining, and program language services, on the same clustered hardware. YARN does this by sitting directly on top of the HDFS, and breaking cluster resource management and job scheduling/monitoring into separate processes.
While that separation does not seem profound, it allows Hadoop to run different data-processing applications and services at the same time. With YARN as the orchestrator, Hadoop is no longer primarily HDFS and MapReduce. Instead it is a variety of data storage, mining and program language services working together, and handling real-time, interactive, batch data processing. For example, Hadoop can work like SQL through Apache Hive or NoSQL through Apache HBase, or it can perform in-memory processing for streaming data through Apache Spark. Such flexibility has made Hadoop the Swiss Army knife of big data storage and processing, increasing its appeal and value to enterprises.
Setting up and maintaining a robust Hadoop framework requires considerable resources and expertise to optimize performance, scalability, reliability, security and ease of use. Many companies leverage Apache’s open source Hadoop solution, providing tailored services to enterprise customers. Amazon [AMZN], IBM, Pivotal Software (EMC/VMW), Microsoft, Teradata [TDC] and Intel [INTC] are established players, while Cloudera, MapR Technologies and Hortonworks [HDP] are leading pure play companies. Hortonworks recently went public, the first pure Hadoop play to do so.
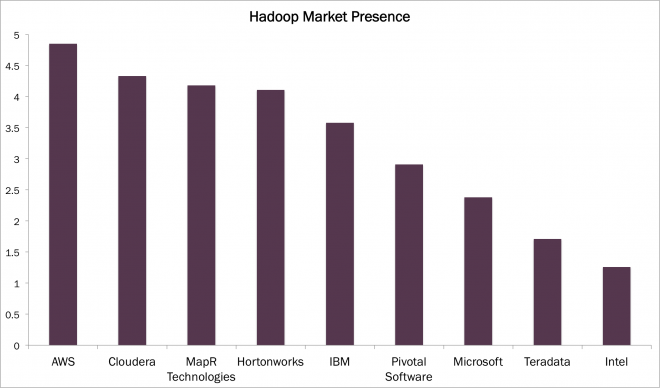
As shown below, Forrester Research rates the market presence of Hadoop on a 0-5 scale, determined by company financials, global presence, installed base, and partnerships. Interestingly, Hortonworks is not that far behind Amazon Web Service (AWS).
Addressing complaints about Hadoop’s complexity, a number of start-ups are focused on ease of use. Altiscale, which recently raised $30M in its Series B, touts its offering as Hadoop as a Service (HaaS). Xplenty advertises no coding required, with a drag and drop system for setting up Hadoop.
On top of these new upstarts, the Hadoop platform itself faces competitors. While these competitors are not as diverse in their utility as Hadoop, they do pose a threat of superior performance in certain use cases, such as near real time processing or analyzing specialized data types. For example, the aforementioned Apace Spark project is typically run on top of YARN, drawing data from HDFS, but it can be broken out from Hadoop as a standalone, pulling from other data stores such as Amazon’s Simple Storage Service [S3]. Additionally, there is Facebook’s [FB] now open source creation, Presto, which is also excellent at rapid data processing, and extremely flexible in the data stores it pulls from. Spark and Presto are better suited to near real-time processing of data, and therefore often referenced as Hadoop competitors. These are just two examples related to near real time processing, but the companies and solutions continue to expand if we turn to data types. For example, Splunk [SPLK] is a more targeted solution for analyzing machine-generated data, or New Relic [NEWR] specializes in Application Performance Management.
With many companies moving into the Hadoop space, big data storage and processing should evolve rapidly. The competition is likely to be fierce, begging the question of whether rapid change will lead to a fragmented market, or “winner takes most.”
Related Research

Google's Driverless Car: A Massive Data Request