 Actively Managed Equity
Actively Managed Equity Overview: All Strategies
Overview: All Strategies Investor Resources
Investor Resources Indexed Equity
Indexed Equity Private Equity
Private Equity Digital Assets
Digital Assets Invest In The Future Today
Invest In The Future Today
 Take Advantage Of Market Inefficiencies
Take Advantage Of Market Inefficiencies
 Make The World A Better Place
Make The World A Better Place
 Articles
Articles Podcasts
Podcasts White Papers
White Papers Newsletters
Newsletters Videos
Videos Big Ideas 2024
Big Ideas 2024
1. The Turnaround Time In Rocket Reuse Suggests That The Cost Of Refurbishing The First Stage Of The Falcon 9 Has Dropped From Roughly $13 Million To $1 Million In The Last Five Years

Rapid rocket reusability is key to lowering launch costs and turbocharging space exploration. In the last year alone, SpaceX reduced rocket reuse time from 27 to 21 days, as shown below.1 If the cost were to correlate with time, which seems likely, our research suggests that the cost to refurbish the first stage of the Falcon 9 rocket has dropped from ~$13 to ~$1 million during the past five years. This improvement, along with other reusability developments, suggests the cost-per-kilogram to low Earth orbit of a reused Falcon 9 is ~$800, compared to ~$2,700 for a new Falcon 9. For historical context, it cost between $450 million and $1.5 billion per launch to refurbish the Space Shuttle.
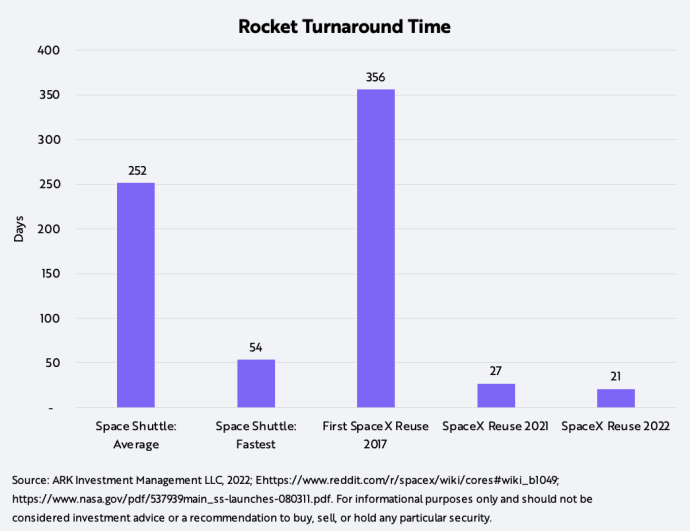
[1] Notably, Rocket Lab also recently demonstrated that it is executing on its key milestones toward rocket reusability.
2. NVIDIA Is Making Strides In Activating Data For Healthcare Decision-Making
Originally developed for the gaming industry, graphics processing units (GPUs) now can accelerate computational tasks like deep learning, which we believe has transformed NVIDIA into a key enabler of the life sciences industry. GPUs allow researchers, for example, to process the data explosion associated with life science tools like DNA sequencers and analyze the complexity of biological systems. In our view, most biological research and clinical workflows eventually will default to GPU-accelerated machine learning algorithms. Last week, the global leader in artificial intelligence (AI) hardware and software systems announced several major enhancements to Clara, NVIDIA’s research ecosystem for the rapidly growing life sciences industry.
The first was its new partnership with a global leader among biomedical research institutions, The Broad Institute. The Broad will integrate NVIDIA’s Clara Parabricks tools for DNA sequence analysis into its own cloud-based research platform, Terra, helping tens of thousands of researchers across the globe. Simultaneously, NVIDIA will optimize Broad’s GATK toolkit, an industry-standard software that identifies genetic mutations, for GPU-based analysis. With Parabricks and Terra, researchers will be able to access first-in-class community algorithms like Google’s (GOOGL) DeepVariant, which we believe will cement NVIDIA’s role as a leading life sciences research platform.
NVIDIA also introduced BioNeMo, a framework that adapts large language models (LLMs) to the field of life sciences. Available in the Clara software suite, BioNeMo will leverage the >500-billion parameter NeMo Megatron LLM to build neural network models around biomolecules like DNA, RNA, and proteins––much like Alphabet’s AlphaFold capabilities. In our view, this technology will lower barriers to entry, enable life science researchers to develop and scale LLMs for biological problems, and accelerate the discovery and development of novel medicines.
Thanks to these advances, we believe the data explosion in life sciences is positioning NVIDIA as a key enabling partner for the foreseeable future.
3. OpenAI Has Released An Open-Source, General-Purpose Speech Recognition Model
Last week, OpenAI released an open-source neural network capable of transcribing audio to text with near-human levels of performance. The release follows the recent rollout of other high-profile open-source projects, including Stability.AI’s Stable Diffusion model.
Trained on over 600,000 hours of audio data, OpenAI’s Whisper model transcribes English into non-English speech and vice-versa. Large language models demand increasingly massive sets of text data, suggesting that accurate audio speech recognition tools will activate important training data. As models like Whisper interface with large language models like GPT-3 seamlessly and accurately, audio data should become critical to the artificial intelligence training process.