 Actively Managed Equity
Actively Managed Equity Overview: All Strategies
Overview: All Strategies Investor Resources
Investor Resources Indexed Equity
Indexed Equity Private Equity
Private Equity Digital Assets
Digital Assets Invest In The Future Today
Invest In The Future Today
 Take Advantage Of Market Inefficiencies
Take Advantage Of Market Inefficiencies
 Make The World A Better Place
Make The World A Better Place
 Articles
Articles Podcasts
Podcasts White Papers
White Papers Newsletters
Newsletters Videos
Videos Big Ideas 2024
Big Ideas 2024

Now that deep learning has turbocharged NVIDIA’s [NVDA] data center business by five-fold in the past two years, competition is brewing. As of 2017 nearly a dozen startups have launched, with the goal of building dedicated chips for deep learning applications. In addition, large public tech companies such as Alphabet [GOOG], Intel [INTC], AMD [AMD], Qualcomm [QCOM], and Apple [AAPL] plan to enter the market for deep learning chips.
Given this intense and growing competition, can NVIDIA maintain its lead in the market for deep learning chips? And, which of the newcomers are best positioned to succeed?
GPUs vs. TPUs
Most of the competition is focusing on the Tensor Processing Unit (TPU)[1] — a new kind of chip that accelerates tensor operations, the core workload of deep learning algorithms. Companies such as Alphabet, Intel, and Wave Computing claim that TPUs are ten times faster than GPUs for deep learning. An explanation for this difference is that GPUs were designed first and foremost for graphics, preventing deep learning operations on a large part of the chip. For example, in NVIDIA’s latest Volta GPU core as shown below, deep learning operations execute on the two Tensor Cores on the right. The various execution units to the left are either lightly utilized or not optimal for deep learning.[2] The new wave of deep learning startups seems to be building chips made entirely of tensor cores and on-chip memory. In theory, such TPUs should reach higher utilization and deliver better performance than a GPU.

Thus far, reality has not caught up with theory. Among the more than a dozen companies building deep learning chips, only Google and Wave Computing have working silicon and are conducting customer trials. While Google claims that its TPUs are significantly more powerful and power efficient than GPUs, independent verification has yet to surface. Google’s second generation “Cloud TPU” likely consumes over 200 watts of power, putting it in the same range as NVIDIA’s GPUs. Wave Computing says its 3U deep learning server can train AlexNet in 40 minutes, three times faster than NVIDIA’s P100 DGX-1 server. While impressive if true, its performance pales in comparison to Wave Computing’s claim that its TPU is 1000 times faster. Curiously, neither company has made its new chips widely available for use, suggesting that the real world performance of TPUs does not compare favorably with that of GPUs.
An important reason why TPUs have not outpaced GPUs is the rapid evolution of NVIDIA’s GPU architecture. Over four GPU generations, NVIDIA has improved the architectural efficiency of its chips for deep learning by roughly 10x. The chart below shows how many transistors are required to deliver one million deep learning operations per second. The lower the transistor count, the more efficient the architecture. If all chip vendors are constrained by the same transistor budget, the design with the best architectural efficiency should deliver the highest performance.
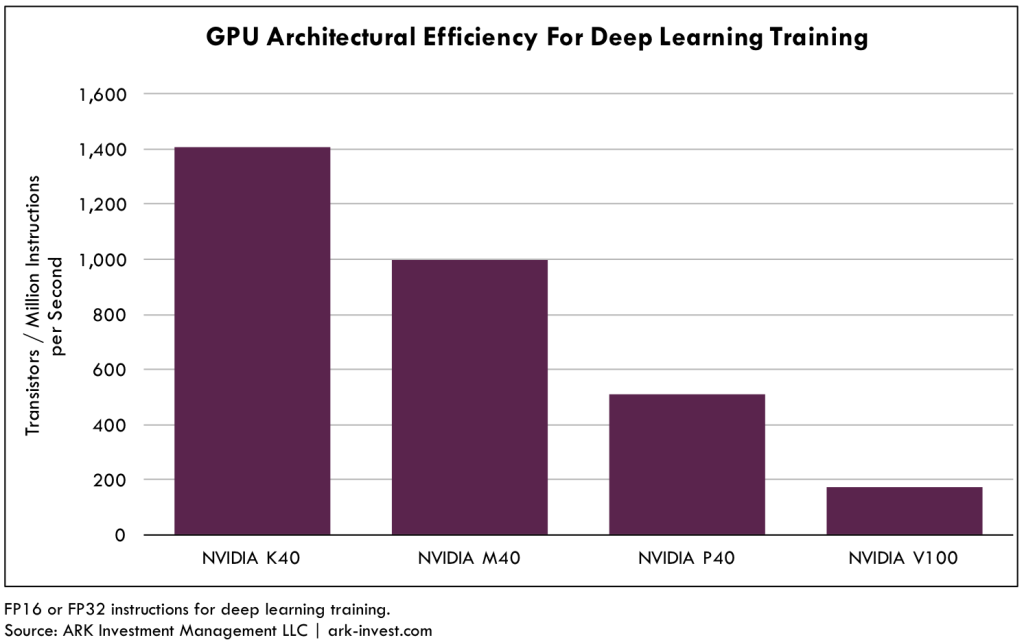
NVIDIA’s K40, one of the first GPUs used for deep learning, required 1,400 transistors to achieve the one million operations per second. Its successor, the M40, removed hardware (FP64 units) not required for deep learning, reducing the transistor count to 1,000 to achieve the same performance. With the P40 GPU, NVIDIA added support for FP16 instructions, doubling the performance efficiency compared to the M40. The newly released V100 chip added a pair of dedicated tensor cores to each data path, tripling architectural efficiency relative to the P40. The fact that NVIDIA has improved the architectural efficiency of its GPUs by roughly 10x in the last few years is the primary reason why thus far TPUs have failed to displace GPUs.
Software
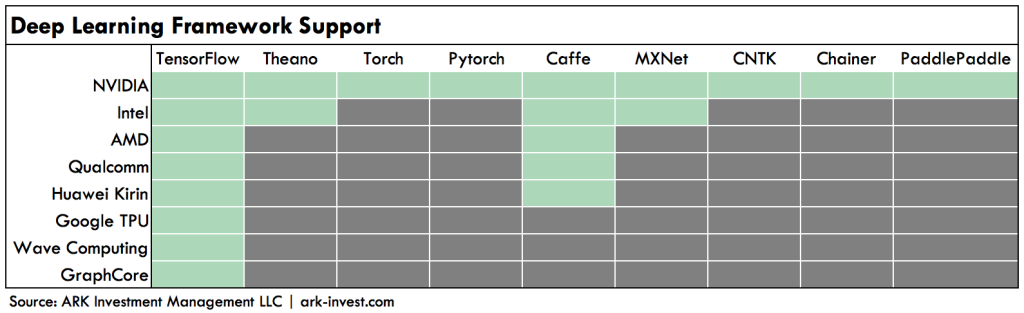
While upstarts may claim an advantage on the hardware for deep learning, NVIDIA has a commanding lead when it comes to software. Unlike graphics, which is dominated by two APIs (DirectX and OpenGL), deep learning is programmed in more than a dozen software frameworks. Each of these frameworks has its champions: Google uses TensorFlow; Facebook [FB] uses Pytorch and Caffe; Microsoft [MSFT] uses CNTK; and Baidu [BIDU] uses PaddlePaddle. Because NVIDIA was first to market, it supports all of these frameworks. Its competitors support mostly TensorFlow and Caffe.
If deep learning programming were to consolidate around one of the leading frameworks, say TensorFlow, NVIDIA’s software lead would become less important as a competitive advantage. Thus far, however, developers have gravitated to a variety of deep learning frameworks, giving NVIDIA a considerable moat against competing vendors.
Deep Learning Chips for Connected Devices
Instead of competing against NVIDIA in the server market, many startups are building deep learning chips for connected devices. This is a nascent market with no entrenched leader and an addressable market on the order of tens of billions of devices per year. Chips for end-devices have power requirements as low as 1 watt. NVIDIA’s SoC (system-on-chip) designs require tens of watts, making them unsuitable for many of these devices. In a way NVIDIA has already conceded this market. In May 2017, it announced that it would open source the design of its Deep Learning Accelerator (DLA), a TPU-like unit on its Xavier chip. By doing so it’s signaling that the devices market is too large and diverse for a single chip design to address, and that customers will ultimately want custom designs, similar to the smartphone market today.
In ARK’s view, new entrants will have the best chance of success in the end-device market. During the next few years, smartphone SoCs are likely to incorporate a TPU logic blocks, much like they have incorporated GPU and modem logic blocks, creating opportunities for new IP licensing companies. Cambricon, for example, has licensed its TPU design to Huawei for its Kirin 970 SoC. Leading SoC vendors like Apple and Qualcomm are developing this expertise in-house and will release SoCs with integrated TPUs over the next one or two product cycles.
Extending well beyond smartphones, deep learning also could open large market opportunities for upstarts like Mythic and Thinci. Although many of them will be acquired, a few of these startups could become the next Imagination Technologies ($500m market cap), ARM ($32b acquisition price), or Qualcomm ($78b market cap).
Looking Ahead

In the 1990s, NVIDIA competed with a dozen graphics chip makers, as shown above, and emerged victorious. Today, it’s facing another dozen competitors in the market for deep learning chips. Despite fending off the first wave of TPU competitors, NVIDIA is not out of the woods yet. At the end of this year, Intel and GraphCore are likely to release their respective TPUs, and potentially a radically different chip design could leapfrog even NVIDIA’s Volta GPU. That said, exotic chip architectures have a poor record in unseating incumbents: Crusoe, Itanium, Cell, Larrabee, and Niagara all were innovative designs that were commercial failures.
Until TPUs demonstrate an unambiguous lead over GPUs in independent tests, NVIDIA should continue to dominate the deep learning data center. As for end devices, startups have plenty of room to revolutionize the market with artificial intelligence. Indeed, the next ARM could be among us today.
Sources
Cover image: Uploaded to https://pixabay.com/en/digital-abstract-binary-code-1742687/ is licensed under CC BY 2.0
Related Research


Could Deep Learning Grow the Robotics Market Ten-Fold (or More)?
