 Actively Managed Equity
Actively Managed Equity Overview: All Strategies
Overview: All Strategies Investor Resources
Investor Resources Indexed Equity
Indexed Equity Private Equity
Private Equity Digital Assets
Digital Assets Invest In The Future Today
Invest In The Future Today
 Take Advantage Of Market Inefficiencies
Take Advantage Of Market Inefficiencies
 Make The World A Better Place
Make The World A Better Place
 Articles
Articles Podcasts
Podcasts White Papers
White Papers Newsletters
Newsletters Videos
Videos Big Ideas 2024
Big Ideas 2024


Google’s [GOOG] autonomous car project is unique not because of the spinning lasers on top of the car, nor its cameras, nor its kill switch. What really sets it apart from other driverless vehicles is the data request, the volume of the data it plans to collect and process to make its cars truly autonomous.[1]
Google plans to map every road in the US, meaning it will need to collect and process 20 to 70 petabytes of data.[2]
For perspective, the storage required for all of the books in the US Library of Congress totaled 235 terabytes as of 2011. Multiply this number by about four and you have just one petabyte! Google needs to collect between 90 and 300 times the entire volume of data stored in the Library of Congress.[3]
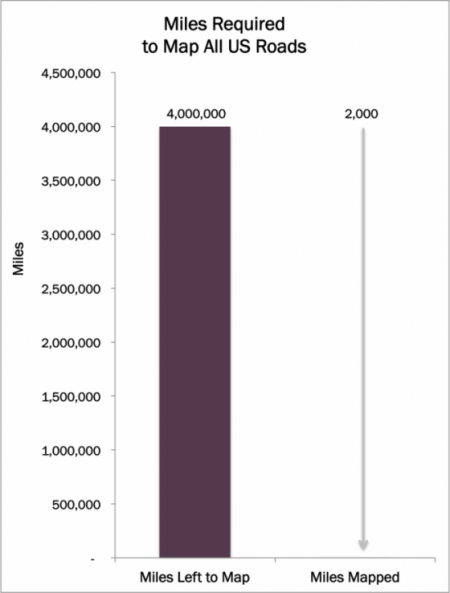
As shown below, so far Google has mapped only 2,000 [4] out of four million miles of roads.[5] Very likely it will not map every road before the car is released in 2019-2020. Company Software Lead, Dmitri Dolgov, said he can imagine a scenario where car owners will help collect the information. Similar to Street View, drivers could help collect data for remote areas.[6] After users collect the data, however, teams at Google still will need to stitch it together.[7]
Other technology companies and automakers rely on vehicle-to-vehicle communication systems, rather than full mapping. Elon Musk, CEO of Tesla [TSLA], said he expects his autonomous car, slated for a 2017 release, to only be 90% autonomous. Gathering the last 10% required to gain full autonomy, he said, will be painstaking.
This last 10% is the gap that Google intends to exploit: fully autonomous as opposed to semi-autonomous. This will take more time to complete, allowing competitors who choose the semi-autonomous route to launch first, as shown below.
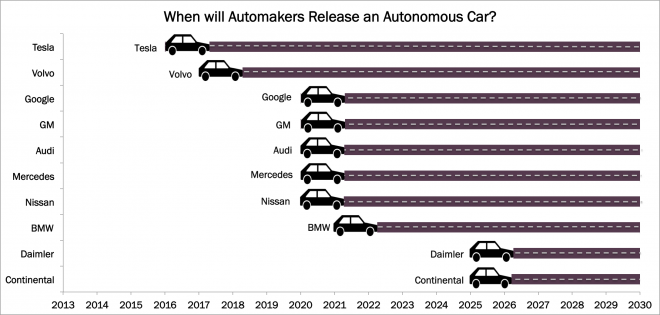
Google recently delayed the timeline for releasing its vehicle to 2-3 years later than the original 2017 deadline.[8] However, even with this setback, the company will still be the first to release a fully autonomous car.
Related Research

Google's Driverless Car: A Massive Data Request
